Connecting Microsoft Business Central to an Azure Data Lake - Part 3
- Jesper Theil Hansen

- Mar 28
- 4 min read
Updated: Apr 10
Part 1 Scheduling of Export and Sync Part 2 Possible timing clashes/conflicts that can corrupt data Part 3 Duplicate records after deadlock error in BC Part 4 Archive old data
After having the BC to Data Lake synchronization running great for some months, we hit an issue twice within a short timeframe.
The Business Central implementation is one that receives a lot of documents from external sources, orders, confirmation documents, invoices etc. These are all sent to Business Central API endpoints and processed through a combination of standard BC logic and custom code. Even standard business central can run into a deadlock when for example doing multiple postings simultaneously, and we see them now and then. Usually it is not a big issue - it can result in a user seeing an error and having to retry an operation, or a system function will have to retry and typically succeed on the next attempt.
Duplicate EntryNo's in transaction tables
Transaction tables like GLEntry, CustLedgerEntry etc. typically have a unique EntryNo field that is controlled by the system, is sequential and unique, marked as AutoIncrement.
According to documentation, these numbers would never be reused, however the documentation leaves a little doubt about how this works:
A table can only contain one auto-increment field. The numbers assigned to this field will not always be consecutive for the following reasons:
- If you delete some records from a table, the numbers used for these records are not reused.
- If several transactions are performed at the same time, they will each be assigned a different number. However, if one of these transactions is rolled back, the number that it was assigned is not reused.
So this makes sense, but what if it isnt several transactions that have "pulled" a new number but just one that ends up being rolled back and no new numbers have been assigned, then you could roll back the numbers and use the discarded numbers for the next transactions.
At least that is how it looks like the system does it, because we did get duplicate EntryNo's exported as deltas. And here is what our investigation showed happened:
The data lake export at time=1:00 exported a record with EntryNo 25001 and data in other fields=X
The next data lake export at time= 2:00 exported a record with EntryNo 25001 and data in other fields=Y
The transaction involving record X had not completed, it had failed with a deadlock error, the transaction was not posted. The error had occurred at time=0:57 There were no GLEntry records for this document
The transaction involving record Y has posted fine at time=1:03 and it had records in GLEntry, one of them being the one with EntryNo 25001
The transaction for records X could be retried, the document posted, and this resulted in successful posting and GLEntry records with new EntryNo's.
Now, two deltas with the same EntryNo had been exported, for two different transactions, and since the data lake does not do consolidation based on EntryNo, but based on the Company and SystemID fields, it added both records to the lake.
Update April 2 2025 :
The assumption about what happened turned out to be correct. I have a reliable repro that will result in duplicate EntryNo's in the export to the data lake. The reason is that the statement quoted above from the documentaion is incorrect. EntryNo's WILL be resused. And the fix is now in the main BC2ADLS repos : https://github.com/Bertverbeek4PS/bc2adls/pull/253
Check for duplicates, and sync on EntryNo
Since this seems to have been a "freak" coincidense, we haven't seen the same error more than twice in almost a year of running, I initially just added a "check for duplicates" pipeline that I run after the main consolidation pipelines have run:
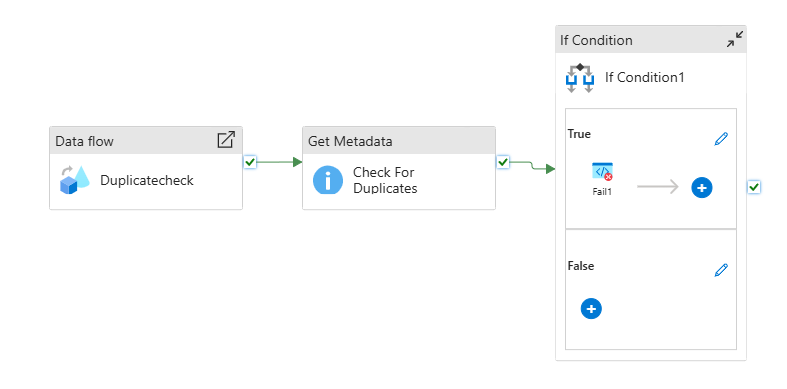
The pipeline runs a dataflow that aggregates all records by EntryNo and outputs any with a count higher than 1 to a csv file. The pipeline checks for the existance of any duplicates there and fails, causing an alert, if it found any.
This is the dataflow:

I only run this for GLEntry after sync, and it hasn't fired more than once so far.
A better solution, but requiring change to the Sync Pipelines is:
Sync on EntryNo instead of SystemID
The pipelines and the main dataflow, being generic for all entities, sync based on SystemID. It is, however pretty easy to change to sync on EntryNo. I have chosen to not make too many changes and overcomplicate the existing pipelines and dataflow so I copied the Consolidation_flow dataflow to Consolidation_flow_entryno and changed just 4 places :
In the two output sections where systemId is defined, add EntryNo-1
(output(
{timestamp-0} as long,
{systemId-2000000000} as string,
{SystemCreatedAt-2000000001} as timestamp,
{$Company} as string,
{EntryNo-1} as long
)Change SystemId to EntryNo in these two lines:
CurrentData derive({$UniqueRecordKey} = concat(toString({EntryNo-1}), iif($perCompanyEntity, {$Company}, ""))) ~> CurrentDataWithUniqueRecordKey
Deltas derive({$UniqueRecordKey} = concat(toString({EntryNo-1}), iif($perCompanyEntity, {$Company}, ""))) ~> DeltasWithUniqueRecordKey
Again, if you dont mind changing the original pipelines, you could add logic to choose the EntryNo dataflow for entities with this pattern and use the original flow for others. I just chose to duplicate Consolidation_OneEntity and create a Consolidation_OnEntity_EntryNo, similar for the other pipelines, and then I trigger this specifically for the entities I want handled like this.
I use the syncGroup features described in part one to chose which entities to call the new flow for.

Comments